This is a nice glitch. @moderators
My post is showing that it’s posted by Craig.
Funny
With a GTX 1650 you should get markedly better results than my laptop.
The sample upscales the video file FH3_540p60.mp4 in folder Media\Videos\Turn10. You can just replace it with a different video in 540p@60fps and it should work (didn’t try myself).
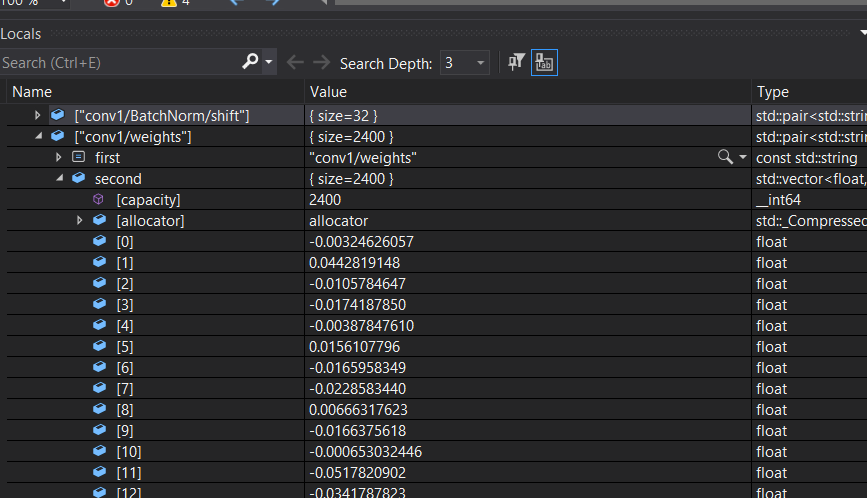
This has not anything to do with the GPU support for INT. The SuperResolution network uses floating point weights. Here, straight from the runtime:
Or maybe i didn’t understand your question correct? sorry, english is not my first language.
What I mean is that direct ML tries to use any hardware available, so it could be that even if they could fit then into an int format they stick to FP16 as that would be faster on a gpu without rpm for int.
Nvidia’s tensor cores aren’t built for SS, they’re built for generalized ML, including training. Their DLSS solution uses both INT4/INT8. Those were added to the tensor cores specifically for stuff like SS where you end up quantizing the data set right off the bat as the weights that get output are all integer values. Doing tensor math on integers will never require FP precision since you can’t multiply integers and get anything other than more integers. I think you are confusing their training (which uses FP16) and how DLSS does inference.
When asked specifically about DLSS/ML in XSS/XSX, this is what Andrew Goosen said:
“We knew that many inference algorithms need only 8-bit and 4-bit integer positions for weights and the math operations involving those weights comprise the bulk of the performance overhead for those algorithms. So we added special hardware support for this specific scenario.”
And of course it matters what part of the frame ML is used. You aren’t using all your GPU resources during each millisecond within the frame’s production.
It sticks to FP16, because floating point is specified as a data type. There is no INT in the example.
I can’t find any source for that. Do you have a link where i can read about its use in DLSS?
But this is not one of the inference algorithms where INT4 will be used and I question the widespread use of INT8 with SuperResolution if NVidia and Facebook engineers don’t use it.
The SuperResolution inference uses almost 100% of the GPU resources when it runs. Nothing else will overlap with it in an efficient manner.
Yeah I’ve included more info below. I wanna note that the super res example uses FP16 since it is showing DirectML using Nvidia’s FP16-trained model. That isn’t the extent of what MS plans to do. As noted, James Gwertzman already confirmed MS is using the INT capabilities specifically for upscaling individual textures and MS has repeated that super sampling is their intended use case there too several times. So unless you think MS is mistaken about their own decisions and research, it seems quite settled to me.
And you don’t need anything to overlap with the SS within the frame time. The rest of the work would be done by then anyhow (since you are rendering much, much fewer pixels in the first place before scaling).
“Microsoft has confirmed support for accelerated INT4/INT8 processing for Xbox Series X (for the record, DLSS uses INT8) but Sony has not confirmed ML support for PlayStation 5 nor a clutch of other RDNA 2 features that are present for the next generation Xbox and in PC via DirectX 12 Ultimate support on upcoming AMD products.”
Some more background on INT8 added to Turing’s architecture from Nvidia:
“Turing GPUs include a new version of the Tensor Core design that has been enhanced for inferencing. Turing Tensor Cores add new INT8 and INT4 precision modes for inferencing workloads that can tolerate quantization and don’t require FP16 precision.”
This also might be worth checking out as well:
“Many inference applications benefit from reduced precision, whether it’s mixed precision for recurrent neural networks (RNNs) or INT8 for convolutional neural networks (CNNs), where applications can get 3x+ speedups.”
Note: DLSS uses a convolutional NN for training.
And this arXiv paper (presumably published elsewhere by now since it’s from April):
“Once trained, neural networks can be deployed for inference using even lower-precision formats, including floating-point, fixed-point, and integer.”
As for accuracy, quantization matters. This research is part of the basis for what Nvidia has been doing with DLSS and other ML uses cases:
“We present an overview of techniques for quantizing convolutional neural networks for inference with integer weights and activations. Per-channel quantization of weights and per-layer quantization of activations to 8-bits of precision post-training produces classification accuracies within 2% of floating point networks for a wide variety of CNN architectures.”
“Quantization-aware training can provide further improvements, reducing the gap to floating point to 1% at 8-bit precision.”
This is really neat!

That’s what i was wondering. The frame has to be completed first, only then it can be used to upscale correctly. I don’t think super sampling will be running in parallel.
Although, i am not sure of using the shaders first for rendering the frame and then using it for super sampling within the given frame time is possible or not. If this can work, then no worries of GPU utilisation or partition.
Is the XBX gpu capable of ai upscaling without the upscaling process itself taking to much gpu time?
This is the real question
Example:
Render in 4k = x time
Render in 640x480 AND upscale = y AND z time
We must assume that y time is way smaller than x time
The question is y AND z combined are also smaller than x time?
For DLSS on Nvidia gpus the answer is a very big yes for all games that support it thus far.
For consoles, I would expect similar results, if a method is too costly for them devs will just switch to something else.
Nvidia’s approach lets them start rasterizing the next frame and more evenly spreads the ML workload out over the frame. Not sure exactly how that works though.
We don’t need to speculate on if it is possible using shaders a la how it will work on XSX…it’s already being done exactly for this kinda thing at XGS. MS didn’t go out of their way to put INT operation capabilities into the shader core so they can do precisely this exact SS without testing and researching and knowing 100% for certain it worked, lol. The question now is how well SS works, how it works with VRS, if the texture upres approach is more efficient, etc.
Just to be clear: We know for certain that it will yield notable improvements to IQ and framerates. How big is anyone’s guess right now, but the speculation around if it is plausible is misguided.
AMD’s offering to MS initially did not include INT8/INT4 capabilities. MS specifically asked those be included ON THE BASIS of already having researched using those capabilities for ML (they even called out SS specifically). They didn’t just guess that it could maybe be plausible, they don’t make decisions about silicone changes with guesswork. They saw how much research was steering towards using INT operations in SS and other ML tasks (that shift started among researchers in 2017/2018). MS is well aware of that and asked AMD to tweak the shader cores after doing their own R&D with it.
They have directly explained this in their DF interview as well as in their marketing for XSX’s ML capabilities. The question is how well will it work and how it combines with other innovations in the platform.
Thanks @TavishHill for the links.
I saw Digital Foundry as the source for INT8, found nothing else. I read a lot of stuff from NVidia about thier solution and they themselfes only mention FP16 performane and metrics, but mostly older material. Could be they improved their solution.
And I thought about precision alot yesterday and you can probably get away with lower stuff (even without quantization of the network weights), because in TAA/DLSS cases the network has only to determine which samples of current or previous frames to reject or accept for a given pixel location (i.e. the trained rectification heuristics)
Regarding the parallel execution of SuperResolution and normale GPU work, this is rather difficult, because SuperResolution uses almost all compute power in the GPU when it runs. So you can interleave it asynchronously with other work, when they don’t use the GPU or only parts of it. This is certainly possible, because normale rendering work doesn’t utilize GPU 100% all the time and some stuff doesn’t use compute a lot, like shadow mapping. But this makes SuperResolution not faster.
Exciting times. Will be very interesting how Microsoft adapts this for Xbox.
The licence in the sample is MIT/Apache, I could not find a mention of NVidia. I thought this very surprising. So this isn’t NVidias model they first demonstrated with DirectML at GDC. Its the one from models/vision/super_resolution/sub_pixel_cnn_2016 at master · onnx/models · GitHub. This isn’t really useful for games, because it only upscales single images without additional temporal information from previous frames and depth and motion buffers.
My guess is they won’t be using it spread out much across the frame time. Nvidia’s earlier work didn’t spread it out either. Since there can be 75% fewer pixels to shade, there should be plenty of time left over in a frame to dedicate to ML work. There’s lots of other ML use cases that can make sense earlier in the frame time too, but those are probably not latency sensitive stuff.
MS has said ML will be used for super sampling, resolution scaling of textures, npc behavior, animation improvements, etc:
“One of the studios inside Microsoft has been experimenting with using ML models for asset generation. It’s working scarily well. To the point where we’re looking at shipping really low-res textures and having ML models uprez the textures in real-time. You can’t tell the difference between the hand-authored high-res texture and the machine-scaled-up low-res texture, to the point that you may as well ship the low-res texture and let the machine do it” -James Gwertzman
“…making NPCs much smarter, providing vastly more lifelike animation, and greatly improving visual quality.” -XSX Tech Glossary article
Also, this is from Hot Chips presentation:
So I think we know what they plan to use it for, just a matter of how well it works in practice and (possibly more challenging) how game designers can make use of it especially for npc behavior.
Wish this was the Backwards Compatibility team, lol. I guess this approach would reduce storage and RAM utilization.
And I/O throughput needs, DL size and SSD footprint. ![]()
I see no reason it couldn’t work on BC games too. Something very similar has been done on PC after all.
For me its when we can expect to see it. I think it is a while away, if it is used at all. Has the smell of PS4 Pro RPM to me.
More fun use cases for ML in gaming (not at run time afaik):

Also, another example EA noted was that Mass Effect’s Remastered trilogy got texture boosts using ML super sampling on those older textures. They upres’d many thousands of textures that way. ![]()
So will Xbox Series X and S get this and will it be a game changer?
Well MS had AMD add additional features to their SOC for this purpose, so hopefully it pans out